Từ dữ liệu đến dự đoán: Khi Drift làm sai lệch mô hình
1.What is Drift ?#
Mô hình Machine Learning được huấn luyện trên dữ liệu lịch sử (historical data). Tuy nhiên, khi áp dụng vào dữ liệu thực tế, có thể xảy ra hiện tượng dữ liệu thực tế không còn phù hợp với dữ liệu huấn luyện do bị lỗi thời, dẫn đến độ chính xác của mô hình giảm dần theo thời gian.
Drift là sự thay đổi theo thời gian trong các đặc tính thống kê của dữ liệu đã được dùng để huấn luyện mô hình học máy. Khi dữ liệu thực tế mà mô hình gặp sau này khác biệt so với dữ liệu huấn luyện ban đầu, mô hình có thể hoạt động kém hiệu quả, giảm độ chính xác, hoặc cho ra kết quả không như mong đợi. Ví dụ: bạn huấn luyện một mô hình dự đoán hành vi khách hàng dựa trên dữ liệu năm 2022. Tuy nhiên, đến năm 2024, hành vi khách hàng thay đổi do thị trường, xu hướng hoặc yếu tố kinh tế. Lúc này, mô hình có thể không còn phù hợp nữa — đó chính là hiện tượng drift.
2.Type of Drift#
1. Concept Drift#
Concept Drift, còn được gọi là Model Drift, xảy ra khi các mối quan hệ (pattern) mà mô hình đã học trong quá trình huấn luyện thay đổi theo thời gian. Điều này dẫn đến việc mô hình trở nên kém hiệu quả hoặc không còn chính xác nữa.
Ví dụ, trong quá trình huấn luyện, mô hình học được rằng:
“Khoảng thời gian từ tháng 6 đến tháng 12 là mùa mua sắm lý tưởng.”
Tuy nhiên, theo thời gian, hành vi người tiêu dùng thay đổi và:
“Cả năm, từ tháng 1 đến tháng 12, đều được xem là thời gian lý tưởng để mua sắm.”
Khi đó, mô hình sẽ không còn phù hợp vì các yếu tố quan trọng mà nó học được đã không còn đúng với thực tế.
Concept Drift có thể được chia thành các dạng nhỏ hơn:
- Sudden Drift: Sự thay đổi xảy ra đột ngột, ví dụ như một chính sách mới có hiệu lực làm thay đổi hoàn toàn hành vi người dùng.
- Gradual Drift: Sự thay đổi xảy ra từ từ, khi hai tập dữ liệu (mới và cũ) cùng tồn tại trong một thời gian trước khi cái mới dần thay thế cái cũ.
- Incremental Drift: Mối quan hệ giữa đầu vào và đầu ra liên tục thay đổi một cách chậm rãi theo thời gian.
- Recurring Concepts: Các mô hình cũ xuất hiện trở lại theo chu kỳ, ví dụ như hành vi tiêu dùng vào dịp Tết hằng năm.
Source: arxiv.org/pdf/2004.05785.pdf
2. Data Drift#
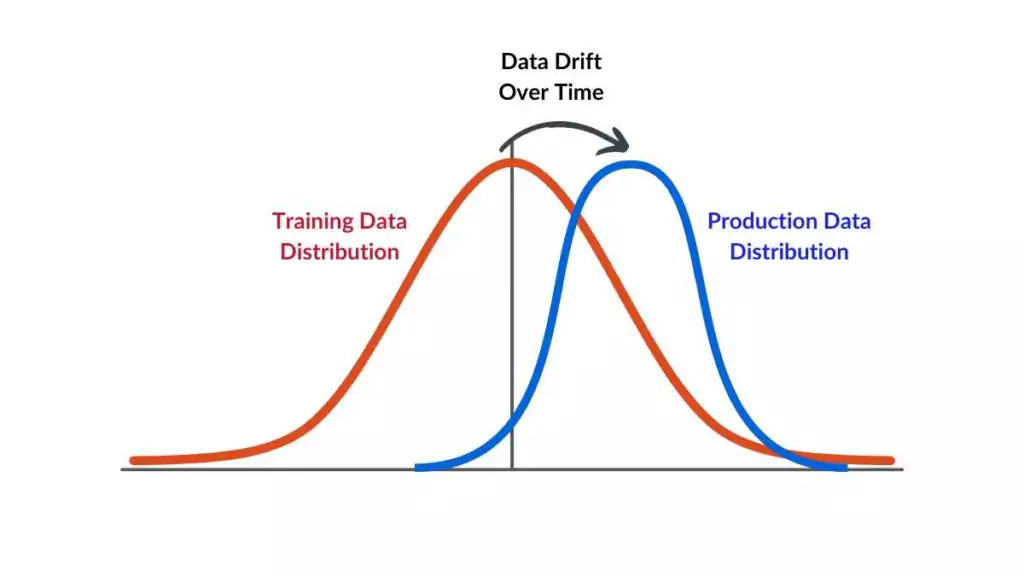
Data Drift, còn được gọi là Covariate Shift, xảy ra khi phân phối của dữ liệu đầu vào thay đổi theo thời gian.
Nói đơn giản, mô hình hoạt động tốt trên thực tế khi thoả điều kiện phân phối trên tập training và trên thực tế giống nhau. Tuy nhiên, dần theo thời gian, một số điều kiện sẽ ảnh hưởng và làm tập dữ liệu trên thực tế có thay đổi về phân phối, dẫn đến mô hình dự đoán sẽ kém hiệu quả.
Ví dụ: Hãy xem xét một mô hình học máy được huấn luyện để dự đoán khả năng khách hàng mua sản phẩm dựa trên độ tuổi và thu nhập. Nếu theo thời gian, phân phối độ tuổi và thu nhập của khách hàng thay đổi đáng kể, mô hình có thể không còn dự đoán chính xác khả năng mua hàng như trước.
3.How to handle?#
- Liên tục giám sát và đánh giá hiệu suất của mô hình theo thời gian (có một số Tool hiện tại hỗ trợ việc monitor mô hình như MLFlow)
- Huấn luyện lại mô hình định kỳ: Có thể schedule lịch training mô hình định kỳ theo hàng tháng hoặc hàng tuần nếu tình trạng drift xảy ra từ từ (gradual drift, incremental drift)
- Huấn luyện lại mô hình khi có trigger: Có thể áp dụng một số phương pháp drift detection theo thống kê hoặc tool → Khi hiệu suất mô hình bị giảm đáng kể thì hệ thống sẽ tự retrain lại mô hình
- Sử dụng phương pháp Online Learning: Hiện nay sẽ có một số mô hình có thể tự cập nhật khi có dữ liệu mới như SGDClassifier, Hoeffding Tree, Adaptive Random Forest,… Tuy nhiên, nên áp dụng khi môi trường dữ liệu có tính thay đổi nhanh và liên tục vì những pattern mô hình đã học trong quá khứ có thể dần bị mất đi (mất importance) khi cập nhật như vậy.
- Ngoài ra, sẽ có nhiều phương pháp khác dựa trên từng tình huống để giải quyết tình trạng Drift.