Cài đặt và setup cụm Apache Spark trên Hadoop 3.3 với VirtualBox
1. Chuẩn bị môi trường ảo hoá#
- Ảo hoá máy tạo các VMs để giả lập các cụm máy chủ
- Tool ảo hoá: Oracle Virtual Box (https://www.virtualbox.org/wiki/Downloads)
- Ubuntu 20.04.6 LTS (https://releases.ubuntu.com/focal/)
1.1 Setup máy ảo gốc#
-
Máy này mình cho làm Master, cài đủ các package sau đó Clone ra các máy phụ sau =)))
-
Thao tác trực tiếp trên Virtual Box (provip có thể sử dụng Vagrant để auto)
-
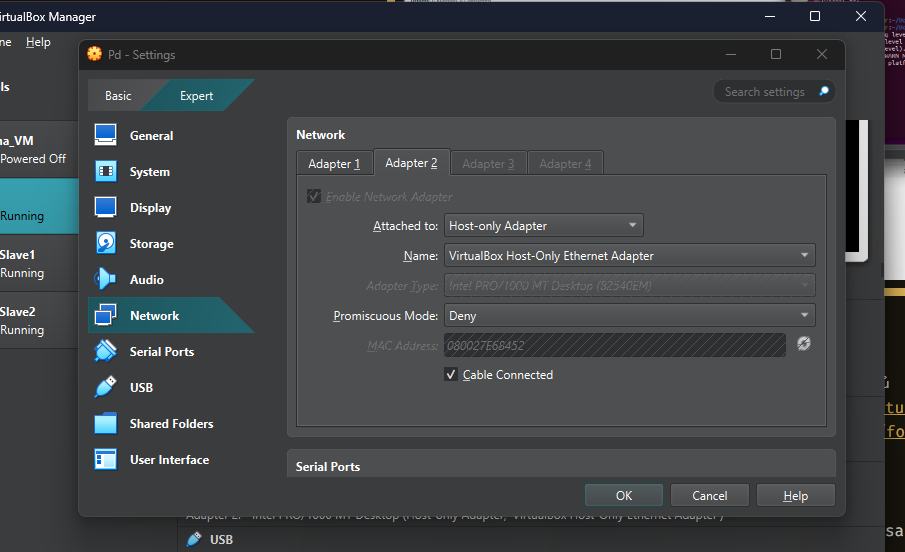
Lưu ý khi tạo máy ảo -> Setting apdapter mạng thành Host-only hoặc Bridge (ko khuyến khích Bridge vì ngồi cấu hình IP hồi rớt mạng ráng chịu)
-
Kiểm tra IP thông với máy host
ip -4 addr show | grep inet
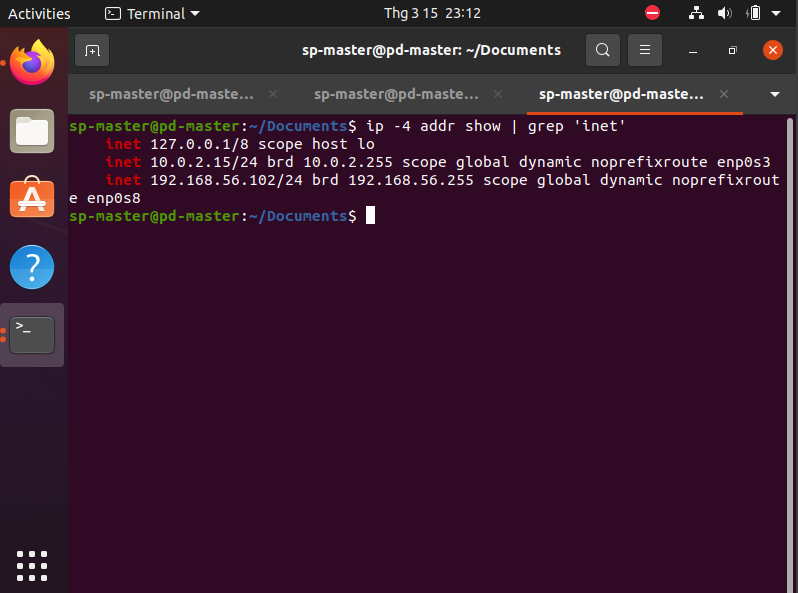 Ở đây địa chỉ được thông với máy host là 192.168.56.102 - Có cùng dãy IP với máy Host (nếu máy host thì kiểm tra trong /ipconfig) hoặc ping trực tiếp từ máy Host đến IP trên.
Ở đây địa chỉ được thông với máy host là 192.168.56.102 - Có cùng dãy IP với máy Host (nếu máy host thì kiểm tra trong /ipconfig) hoặc ping trực tiếp từ máy Host đến IP trên.
1.2 Cài đặt một số package chung#
Java#
Lệnh cài đặt
sudo apt-get update
sudo apt-get install openjdk-11-jdk
Kiểm tra cài đặt
java -version
Kiểm tra path java
readlink -f $(which java)
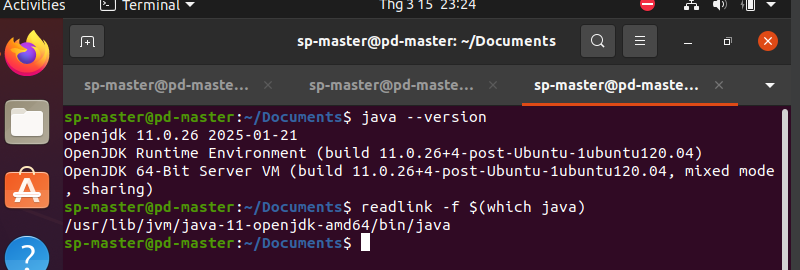
Trong đó đường dẫn /usr/lib/jvm/java-11-openjdk-amd64/bin/java là đường dẫn HOME_PATH của java -> Nhớ lưu cái này để xíu setup.
Scala#
Cài đặt scala
sudo apt-get install scala
Check version scala
scala -version
Apache Spark#
=))) Phần chính 🤡
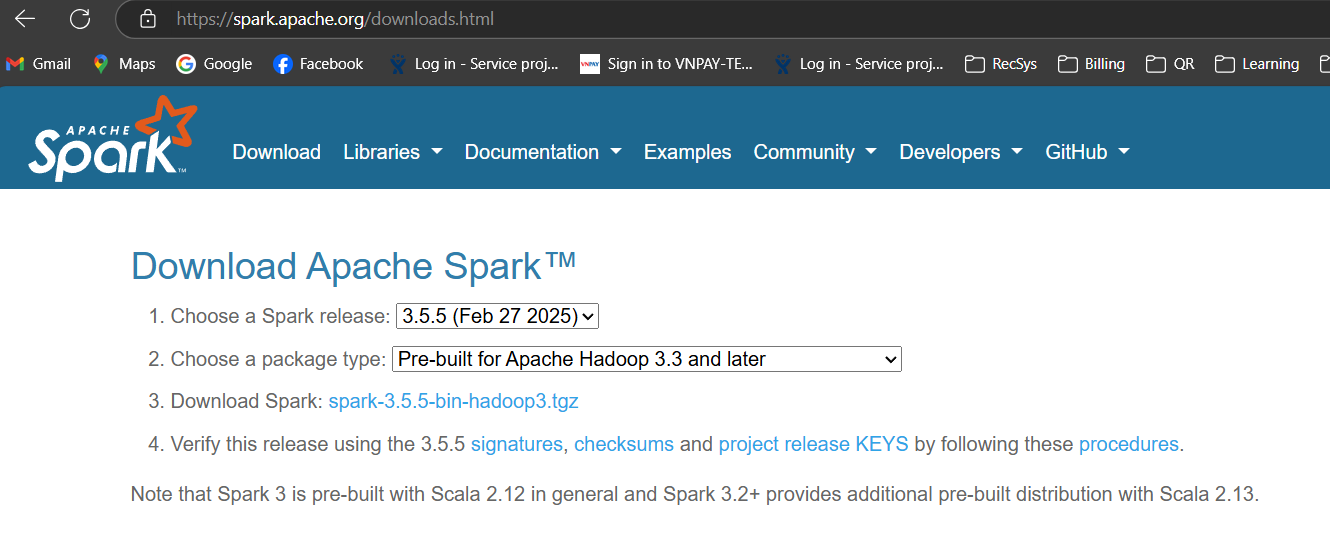
Truy cập https://spark.apache.org/downloads.html chọn version phù hợp ở đây mình chọn bản prebuild cho Hadoop 3.3 -> Spark phiên bản 3.5.5
Kéo file về bằng wget
wget https://dlcdn.apache.org/spark/spark-3.5.5/spark-3.5.5-bin-hadoop3.tgz
Giải nén tệp .tgz với spark-3.5.5-bin-hadoop3.tgz là tập vừa kéo
tar xvf spark-3.5.5-bin-hadoop3.tgz
Move folder đã giải nén vào path /usr/local/spark
sudo mv spark-3.5.5-bin-hadoop3 /usr/local/spark
Thêm spark path vào môi trường hệ thống (tương tự set enviroment variables trong Window)
sudo nano ~/.bashrc
Với file .bashrc chứa các biến môi trường của hệ thông, thêm vào file
export PATH=$PATH:/usr/local/spark/bin
Apply biến
source ~/.bashrc
Kiểm tra spark đã được thêm vào môi trường
which spark-shell

Vậy ta đã setup một số thư viện cần thiết cho một cụm
2. Clone VMs và thiết lập connection giữa các cụm#
Clone VM gốc đã được tạo ở trên thành các worker, số lượng bao nhiêu thì tuỳ theo options người dùng. Ở đây mình clone thêm 2 bản đặt tên là Slave1 và Slave2 và cụm được setup ban đầu sẽ là Master.
2.1 Set lại hostname (tuỳ chọn)#
- Ở đây mình set lại hostname để tiện quản lý =)))
- Với cụm master được hostname là pd-master
- Các cụm worker được hostname là pd-slave-1 và pd-slave-2
Cú pháp chuyển hostname
sudo nano /hostname
sudo hostnamectl set-hostname pd-master #Tuong tu voi slave-1, slave-2
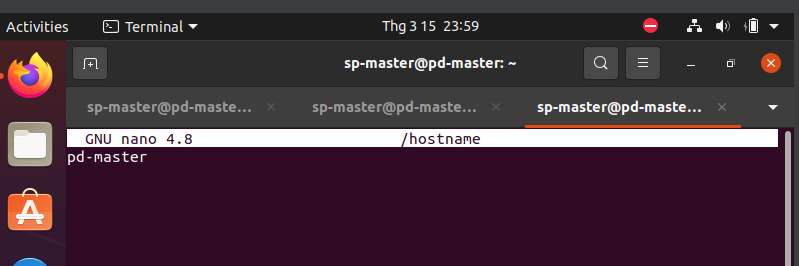 Reboot để thấy hostname thay đổi
Reboot để thấy hostname thay đổi
sudo reboot
 Với pd-master là hostname mới, ở đây mình đổi từ trước nên các các lệnh ở hướng dẫn trên đều mặc định là pd-master
Với pd-master là hostname mới, ở đây mình đổi từ trước nên các các lệnh ở hướng dẫn trên đều mặc định là pd-master
2.2 Add hosts cho master và slaves#
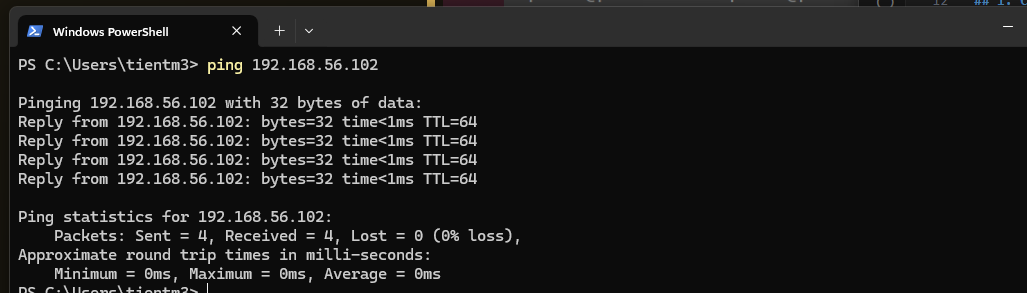
Như cú pháp kiểm tra địa chỉ ip như phần 1 đã hướng dẫn ta lần lượt có các địa chỉ như sau:
192.168.56.102 pd-master
192.168.56.103 pd-slave-1
192.168.56.104 pd-slave-2
Thêm vào file hosts từng VMs để chúng biết địa chỉ phân giải khi ta gọi các máy bằng hostname
sudo nano /etc/hosts
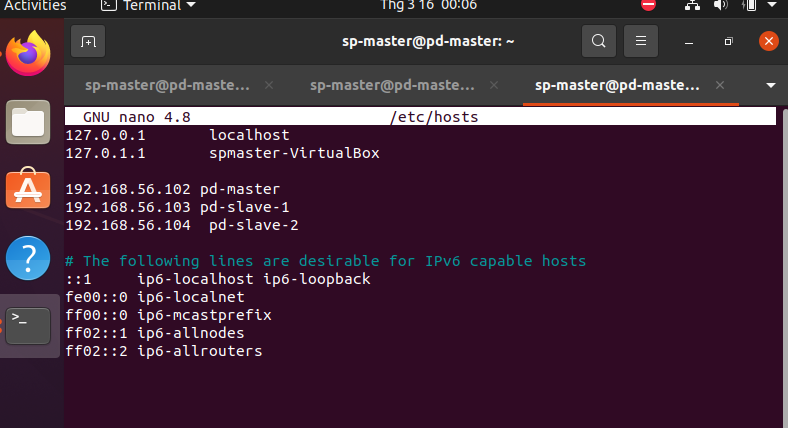
Save và kiểm tra hosts được thêm bằng cách ping từ một VM bất kỳ đến các VMs còn lại

3. Setup máy Master#
3.1 SSH đến Slaves#
Config SSH cho máy master sử dụng ssh-keygen để đặp nhập thay vì password vì lý do bảo mật + nhanh và tự động hơn.
Cài đặt Open SSH Server-Client
sudo apt-get install openssh-server openssh-client
Generate key pairs
ssh-keygen -t rsa -P ""
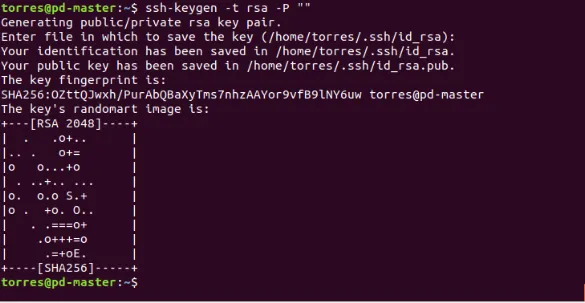
Đẩy key vừa tạo vào authorized_keys
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
Đưa ssh-keygen vừa được tạo vào key được truy cập của cả máy master và các máy slaves
ssh-copy-id user@pd-master #Thay user bang account name
ssh-copy-id user@pd-slave-1
ssh-copy-id user@pd-slave-2
Kiểm tra ssh từ máy master đến các máy slaves
ssh pd-slave-1 # Test ssh den slave 1
ssh pd-slave-2 # Test ssh den slave 2
3.2 Spark config cho Master#
Chuyển đến thư mục config của Spark
cd /usr/local/spark/conf
Copy template config của spark vào cùng thư mục
cp spark-env.sh.template spark-env.sh
Giờ là lúc config =)))
sudo nano spark-env.sh
Thêm đoạn này vào (thay địa chỉ và đường dẫn)
export SPARK_MASTER_HOST='<MASTER-IP>'
export JAVA_HOME=<Path_of_JAVA_installation>
Với MASTER_IP với máy master như ví dụ là 192.168.56.102 và JAVA_HOME là /usr/lib/jvm/java-11-openjdk-amd64/bin/java.
3.3 Thêm workers#
Trong cùng thư mục /usr/local/spark/conf
sudo nano slaves
Thêm nội dung như sau
pd-master
pd-slave-1
pd-slave-2
3.4 Khởi động Spark Cluster#
Trên máy Master
cd /usr/local/spark
./sbin/start-all.sh

Lệnh stop
./sbin/stop-all.sh
4. Kiểm tra cụm Spark#
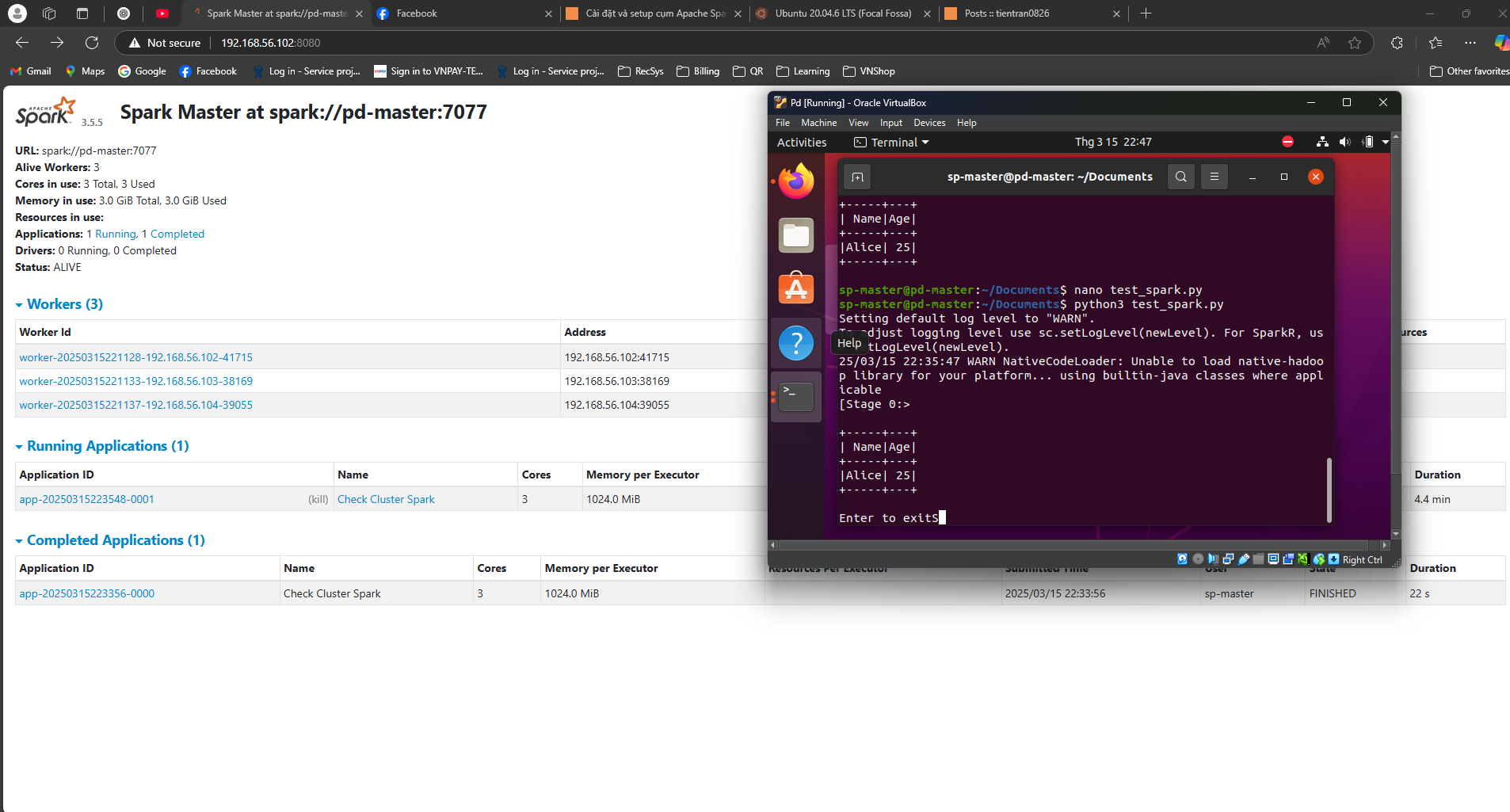
4.1 Spark UI#
Kiểm tra thông qua Spark UI, từ máy host hoặc trên các VMs truy cập
http://<MASTER-IP>:8080/
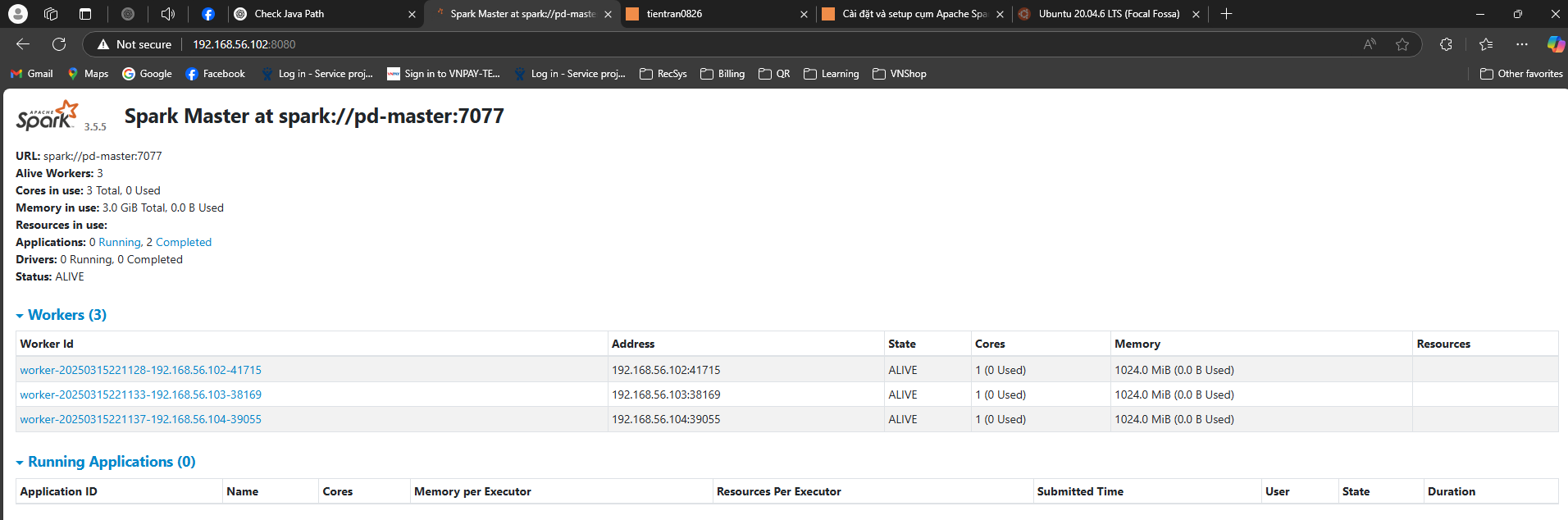
4.2 Check qua code#
- Lười cài JAVA trên máy host quá nên mình test code trên máy Master luôn.
- Note: Nhớ cài pyspark =)))
nano test_spark.py
Code demo:
from pyspark.sql import SparkSession
import os
spark = SparkSession.builder\
.appName("Check Cluster Spark)\
.master("spark://<MASTER-IP>:7077)\
.getOrCreate()
data = [("Alice",25)]
df = spark.createDataFrame(data, ["Name", "Age"])
df.show()
# Them cai nay de hoi chay file py trong command khong bi end session ngay lap tuc
input("Inter to exit")
Kết quả: